In a previous post, we have explained the basics of this topic: What is web scraping, and how would you program a software that performs web scraping?
Alas, programming is a special skill that needs some time and effort to be mastered. We have also introduced in another post the declarative web scraping language OXPath, which can help non-programmers to get a web scraper up and running in less time.
In Smart Harvesting II, we had asked ourselves: What kind of tool would a librarian need to be able to extract bibliographic metadata from the Web? In the beginning, we focused on OXPath, but we soon realized, that even though this declarative language is easier to read and write than a script in a full-blown programming language, there are still some hurdles involved that render OXPath not the best alternative for our user group.
In addition, we realized that, in the meantime, there are a good deal of web scraping tools suitable for the layman available.
In this post, we want to give an overview on the - in our view - most promising web scraping tools.
Test Websites
For the evaluation of web scraping software below, we have used test websites that are specifically designed to test the capabilites of web scrapers. They are functional mockups providing challenges for web scrapers such as login, pagination, user input, AJAX requests etc.
https://www.webscraper.io/test-sites
Web Scraping Tools for the Layman
You have already learned that you can program a web scraper by yourself. For interactive pages, this means to imitate each interaction with the website programmatically. Additionally, you have to identify the location of your desired data in the DOM tree, for example by using web developer tools, and create a path addressing these locations, e.g. via XPath expressions or CSS selectors.
Web scraping tools with graphical user interfaces (GUIs) are designed to encapsulate these steps and present the user only with the view of the web page as it would look like in a regular browser (more or less), enhanced with additional elements for the user to design an extraction workflow. How exactly this is done varies from software to software. The general idea however is the same: The user defines an extraction workflow via point and click, which the software translates into hidden code that is then executed to perform the actual extraction.
While the general principle is the same, different tools vary in some aspects. The most relevant criterion is the mode of installation: Some tools are standalone applications that have to be installed into the system, while others are provided as plugins for web browsers like Chrome or Firefox. In case of standalone applications, there are often restrictions on the operating systems (this mostly depends on the programming language that the software is written in). Most of the tools only run on Windows, some on Windows and MacOS. A minority is also available for Linux. Another very important aspect is the cost - some tools are free, while others have a specific pricing model, for example depending on how many data can be scraped at once, or what level of support is offered. Often, there is a limited trial version available to test the product before subscribing to a paid plan.
Other minor differences in the tools are for example the availability of different output formats or usage of local computing power vs. cloud computing. In the following, we will have a look at a selection of tools and their capabilities, which we have tested with the test websites mentioned above.
Standalone Tools
Octoparse
Octoparse is a web scraping software available for Windows. The .NET framework is required - if it’s not installed, the Octoparse installer will make up for it.
The pricing model includes a free plan, where unlimited installations and pages are included, but export of results is limited to 10,000 records, with only 2 scrapers being able to run concurrently and 10 configurations in total.
The standard plan starts at $75/month.
The paid plans offer (besides more parallel runs and bigger export sizes) additional features such as cloud usage, IP rotation, scheduled execution or API access.
Individual discounts are available, as well as a 14-day trial version of a paid plan.
To use Octoparse, even in the free plan you need a user account. There is a community that can help you get started or answer specific questions on your project. Tutorials are also available, both for getting started with Octoparse as well as for special topics such as dealing with logins, infinite scrolling or setting up proxies.
Octoparse offers two modes of operation: Wizard mode and Advanced mode. As these names suggest, Wizard mode is used to guide the user through the process of scraper definition by providing a predefined set of options for the user to choose at each step. If some fine-tuning is needed, Advanced mode can be switched on after completing the wizard. There are also plenty of template workflows available that can serve as examples and also be adapted to similar use cases.
In Advanced mode, the user is presented with a graphical representation of the extraction workflow, where elements can be added, rearranged and deleted via drag&drop. Even in this mode, the user is guided how to construct his workflow by so-called “action tips” that are context-aware. For example, after selection of an element in the web page, tips such as “Extract text of the selected element”, “Click selected element” or “Loop click selected element” are presented. A click on a tip adds the selected action to the workflow.
More advanced options include the adaptation of generated XPath expressions (including an XPath tool) as well as of the extracted data, inluding a tool to design regular expressions.
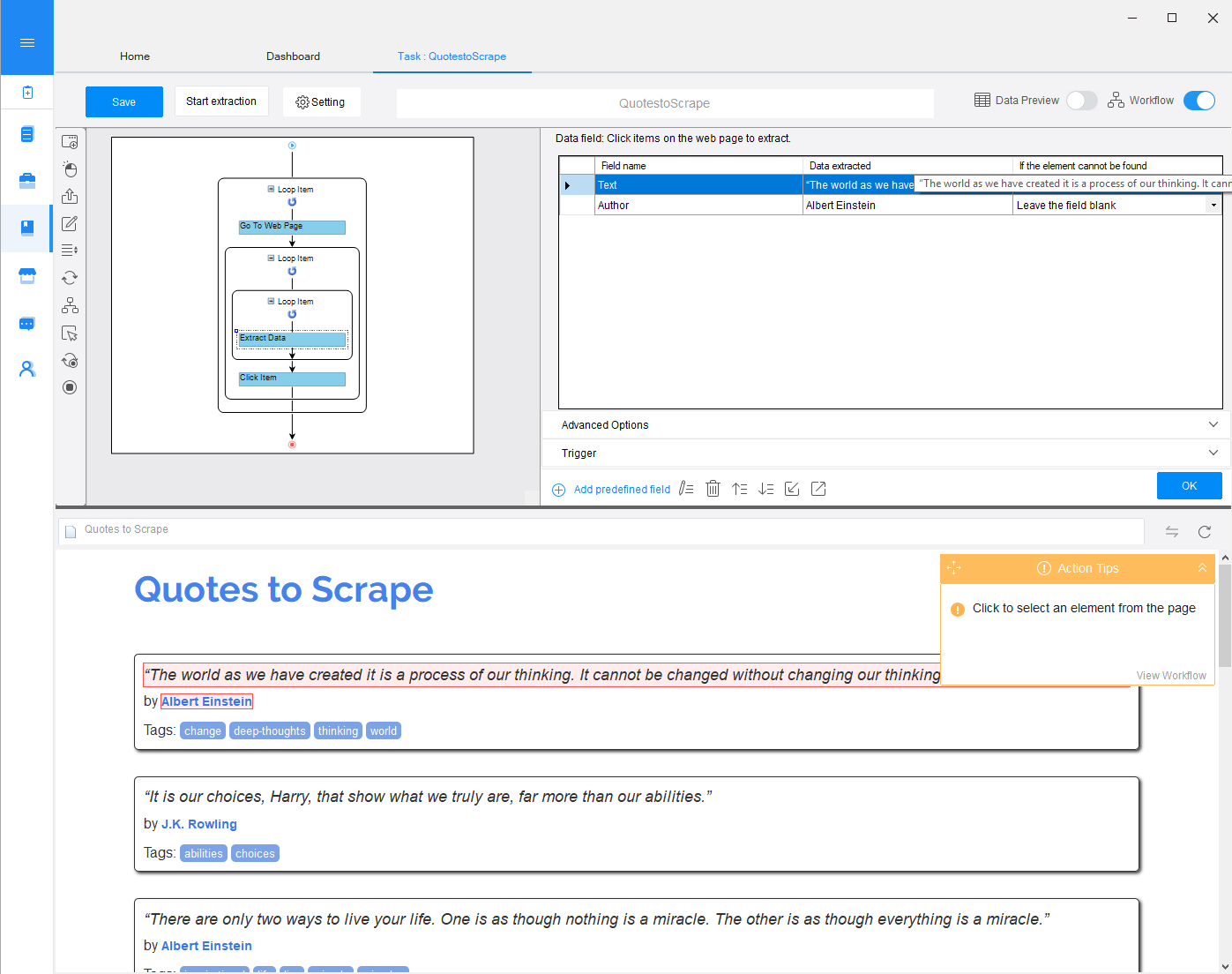
When the workflow design is finished, the extraction can be started. A new window opens where the user can follow Octoparse’s steps navigating the website and extracting the data. If everything went as expected, the result data can be exported as e.g. Excel, CSV or JSON, or into a database.
Octoparse is a user-friendly tool with an intuitive design. An extensive set of tutorials, the community help as well as context-aware guides in the tool help even inexperienced users quickly get their first scraper up and running. A big plus is the availability of a cost-free version with lax limitations that might not pose a problem in simple use cases.
Minor challenges for Octoparse are dynamically created dropdowns, as well as tabular data.
Mozenda
Mozenda provides a desktop application for Windows, the so-called “Agent Builder”, which is used to design the web scraper (called agent), which is then run on Mozenda’s servers in the cloud. The application is connected to the Mozenda Web Console which can be used to manage the defined agents, run scraping jobs, and view, organize, export or publish the extracted data. A user account is required.
The pricing model is basically a credit-based system: different actions consume a different amount of credits, of which each plan has a specific contingent. In addition, plans differ in the number of agents that can be defined, the number of projects, user licences, size of cloud storage and availability of some features such as API access. Plans start at $250 per month. A 30-day trial version is available that allows for 2 users, 5 agents and 2 concurrent jobs, with 500 credits provided.
After entering a URL into the Agent Builder, the page is loaded. You can navigate the page if needed until you reach the target page to start the extraction process. To do this, you click the “Start a new Agent from this page” button. Now the view changes and you are provided with an interface that helps you designing your scraper.
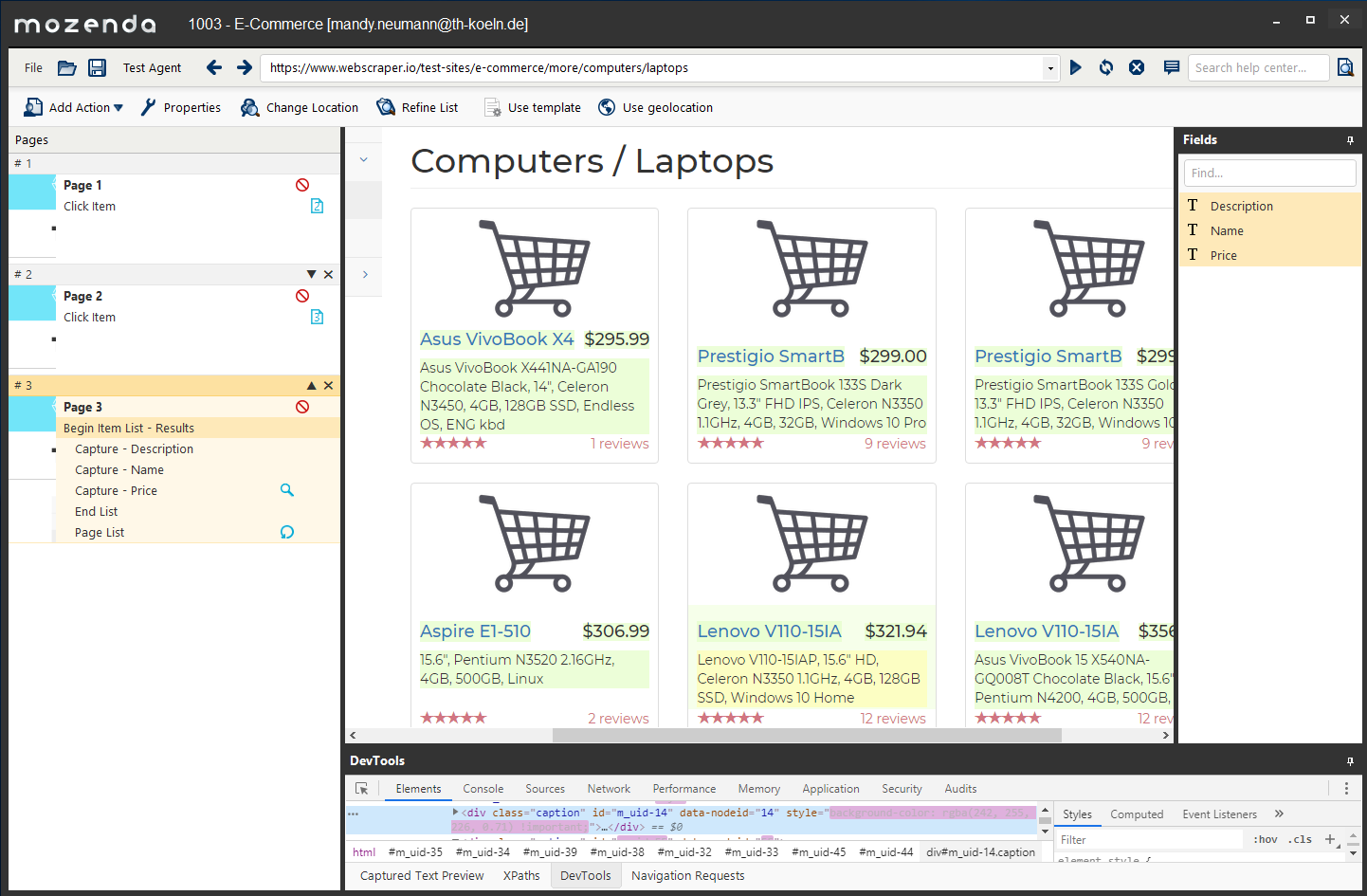
When you are finished creating the scraper, and tested it with the Agent Builder, you can use the Web Console to run it and get results. Possible export formats are CSV, TSV, XML, JSON and Excel. You can also connect to your Dropbox or Google Drive. Scheduled execution is possible.
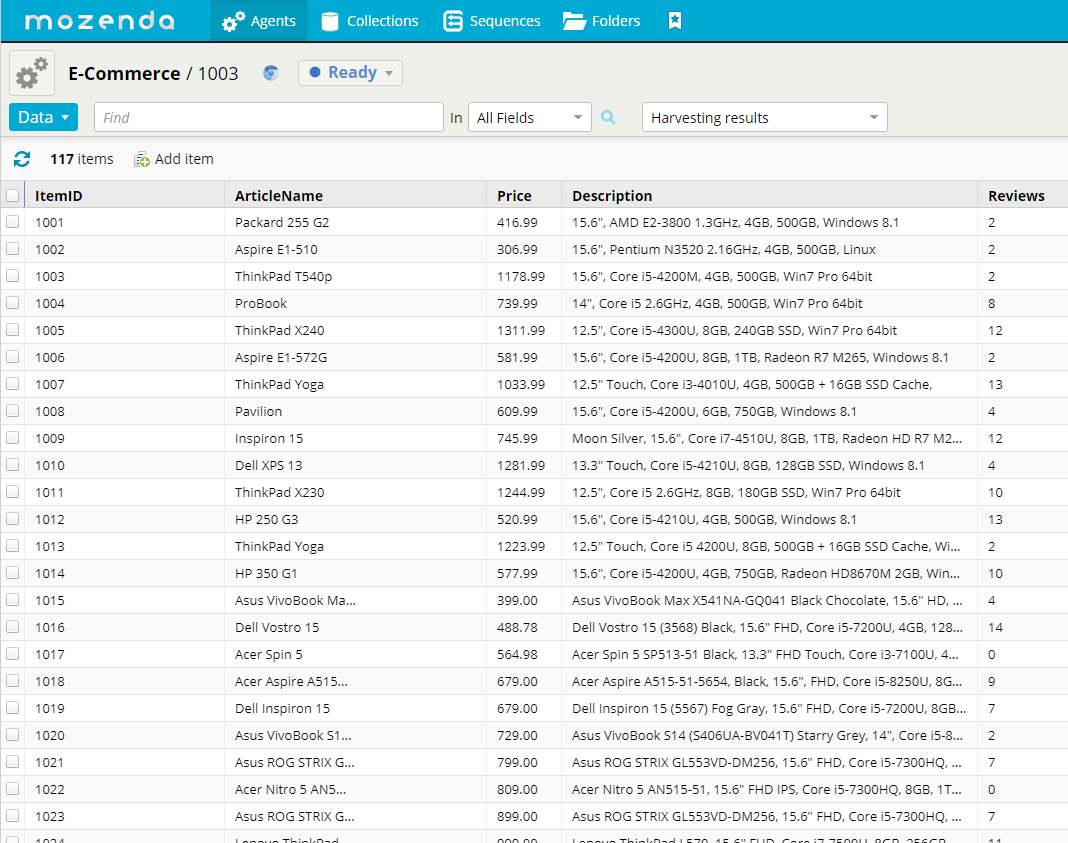
The most recent version of Mozenda’s Agent Builder includes an adapted Chromium Browser, which is not only faster, but also provides access to Chromium developer tools. This allows experienced users to have better control over the extracted elements.
Mozenda is a very intuitive web scraping tool for beginners. The user interface looks clean and modern, and the help center contains helpful articles and videos to get you started. With our test websites, we did not experience any difficulties.
WebHarvy
Another software for the Windows OS is WebHarvy. In contrast to most of the other tools, its pricing model is solely based on the number of licences you buy - a single user licence (up to 3 devices) starts at $129, a licence for unlimited users and devices, e.g. for an organization, costs $699. All licenses come with free updates of the software for 1 year. The software can be evaluated for free for 15 days, with the limitation that only two sites can be extracted.
WebHarvy’s user interface appears a bit outdated, compared to the previous tools, but there are plenty of help articles and video tutorials in the knowledge base to help you get familiar with it and its capabilities. Unfortunately, in contrast to the other tools, there is no workflow view of any kind, so you basically have to remember all your steps while creating the wrapper.
WebHarvy provides all necessary functions to interact with and extract from most modern web pages: follow links, click, input text, scroll to load, click to load more, select dropdown options, deal with pagination, capture target URLs and capture text. It is also possible to download image files from web pages. The Chrome Developer Tools are integrated into the interface for more experienced users. They can also run custom JavaScript on a page.
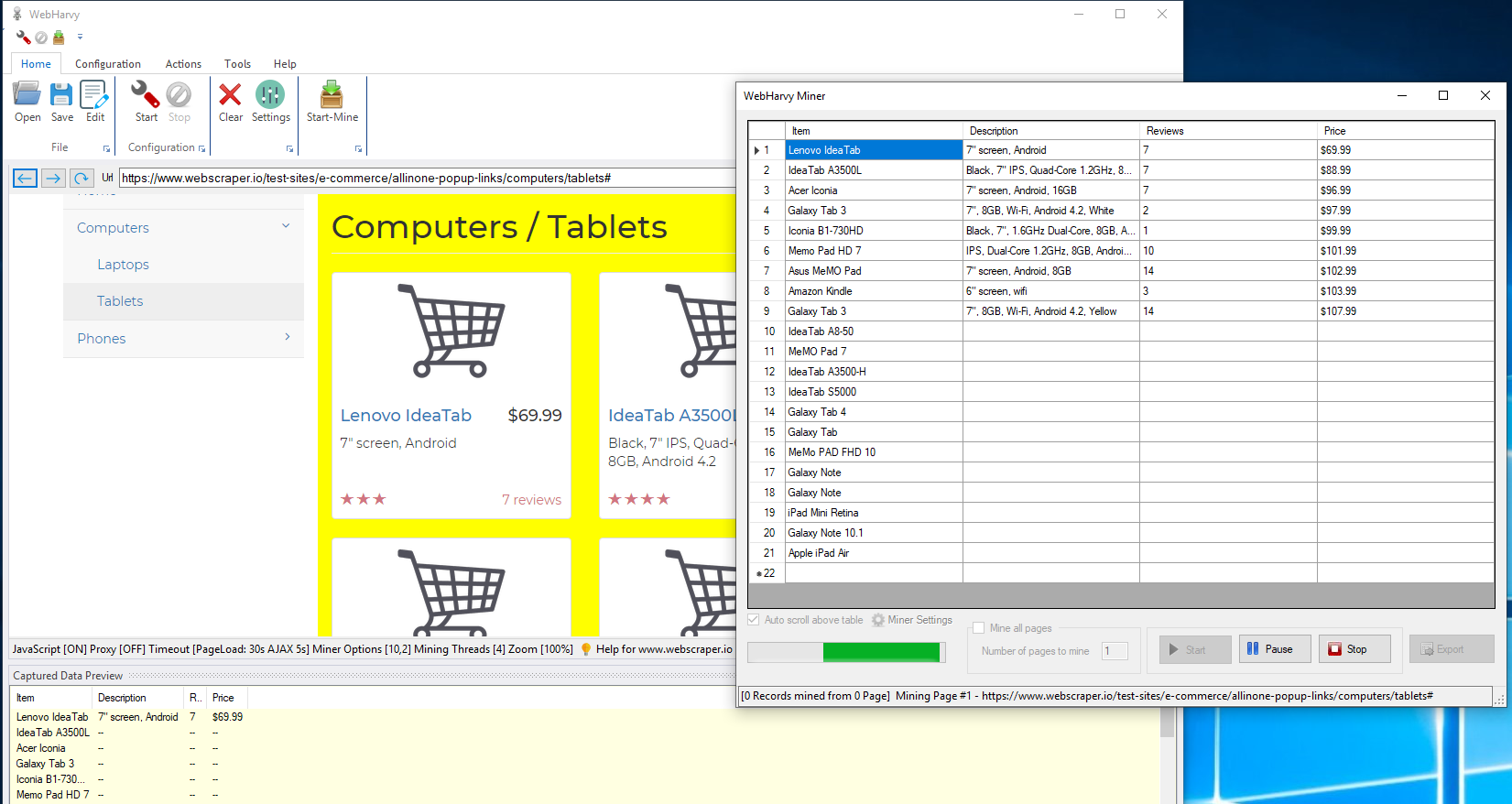
A designed wrapper is called a configuration and can be saved as such in XML format. This allows the user to run a predefined wrapper from the command line. Extraction can also be scheduled.
Besides the user interface not being as fancy as some others, WebHarvy is a nice web scraping tool that can be used for most web scraping scenarios. Limitations relate to dynamic dropdown menus - WebHarvy can only deal with dropdown menus when you provide it with predefined options to choose. This might be a limitation only in a small number of cases. Also, tables pose some problems, which is the case for most web scraping tools when the table design is messy.
In comparison to other tools, WebHarvy is rather inexpensive since there is no monthly fee, but only a single fee for a licence. It is also updated regularly, e.g. the latest version 6.0.1 just came out in January 2020.
Visual Web Ripper
Visual Web Ripper is another Windows software (requiring IE9 or above) with a pricing model based on licences - a single licence costs $349. The evaluation period is 30 days, where up to 100 records can be extracted. There is also a premium version that provides more features which is marketed separately as the “Content Grabber” (https://contentgrabber.com). The following description relates to Visual Web Ripper.
Visual Web Ripper is different from most other web scraping tools in that it does not utilize the concept of some “macro-style approach” or workflow with a sequential list of commands. Instead, everything revolves around “template” and “content” concepts, where templates define how to navigate through a website, and content elements define what data should be extracted from a webpage. A single project can consist of multiple templates, that can contain content elements or sub-templates.
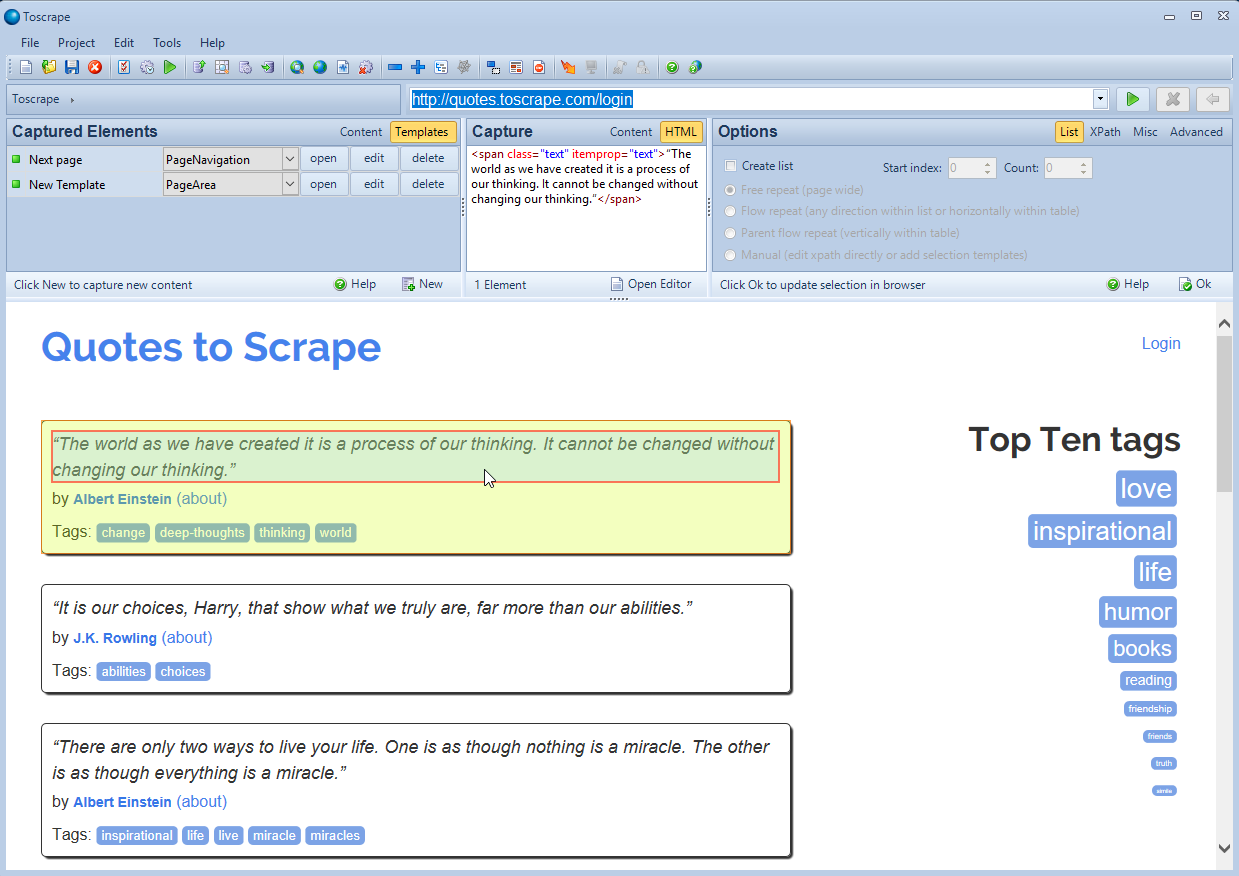
Although the user interface seems a bit unintuitive at first, an extensive manual is available that explains all the concepts and includes some practical tips and examples. In fact, the user interface is also rather rich compared to other tools, and provides the user with a lot of settings and advanced options to fine-tune the templates.
Interesting additional capabilities are an HTML/DOM tree viewer to fine-tune selections, as well as a special debugger that can be used to test the project, including log output and pause/continue actions to step through. In the final extraction, the web browser can be configured to run in foreground or in background. Extraction results can be exported into a variety of formats, such as CAV, XML, Excel files, into a variety of databases, or as a PDF report.
Additional control can be gained via an API for .NET programming languages, which is nice for expert users.
One concern we have with the Visual Web Ripper is the fact that the manual was last updated in 2014, and there’s no information available on when the current version of the tool itself has been released. Judging from the system requirements and the look&feel of the UI, this might have been some time ago. Maybe Content Grabber is a suitable alternative for professional projects.
Diggernaut Excavator
Similar to Mozenda, Diggernaut provides both a desktop application as well as a web console to configure and monitor scrapers. In fact, it is possible to define a scraper (called a “digger”) solely via the web interface via some domain-specific language - a concept very similar to OXPath. There is a public, free to use, repository on GitHub with configurations for scraping various e-commerce websites and online stores. The desktop application, on the other hand, provides a visual interface to create a scraping configuration just like the other tools. It is available for Windows, MacOS and Linux.
The user interface of the tool (called Excavator) is a bit unintuitive, and also rather minimalistic. Diggernaut itself states that it “can be used in limited cases and is not suitable for solving complex problems”. For more complex problems, you probably have to resort to using the Diggernaut meta language.
Our tests confirm that the visual Excavator is rather limited in its capabilities. For example, we could not realize page login or filter data via dropdown menus. In general, Javascript generated content posed a problem, thus also AJAX-based pagination could not be handled. Load scrolling and reloading a page is rather cumbersome to realize. Judging from the documentation, the mata language is indeed much more powerful, so we assume that all these interactions can be realized by scripting the extractor. Thus, Diggernaut is a tool only for basic extraction tasks, or for advanced users.
Diggernaut’s pricing model, similar Mozenda’s and Octoparse’s, is based on providing more projects and requests at higher-priced plans. A free plan is available that allows for only one project, with 3 scrapers and limited to 5,000 requests. The smallest paid plan starts at $75/month. Scheduling extractions is only available in paid plans.
Plugins and Cloud Services
ImportIO
Import.io is a cloud service for web data extraction. That means it is independent of the user’s OS since all that is needed is a web browser to access the web application. A user account is required to use the service. The pricing model includes both a free as well as several paid plans. The free plan is limited to 1,000 queries and limited in features. Unfortunately, it also doesn’t allow recording website interactions (i.e. clicks, form fills etc.), which are essential to modern interactive websites.
Paid plans start at $299 per month. They include API access to access the extracted data programmatically,
After login, a new sraper is created simply by providing the url to the target website. ImportIO first tries to guess on its own which data to extract and presents the results when it’s finished. Afterwards, the user can check if the extracted data fits the requirements. If not, the scraping workflow can be edited.
On first access, a tour that guides through the user interface is automatically opened. The editor window’s design is pretty straightforward. Everything revolves around the target table structure of extracted data. That is, if you need to change what data is extracted to a specific field, simply click the respective column in the “Edit” tab. In this tab, the web page is presented with the target data for that column highlighted. You can then proceed to refine the extraction e.g. by applying regular expressions or adjusting the XPath. You can also rename the column, add and delete columns, or start over with an empty table.
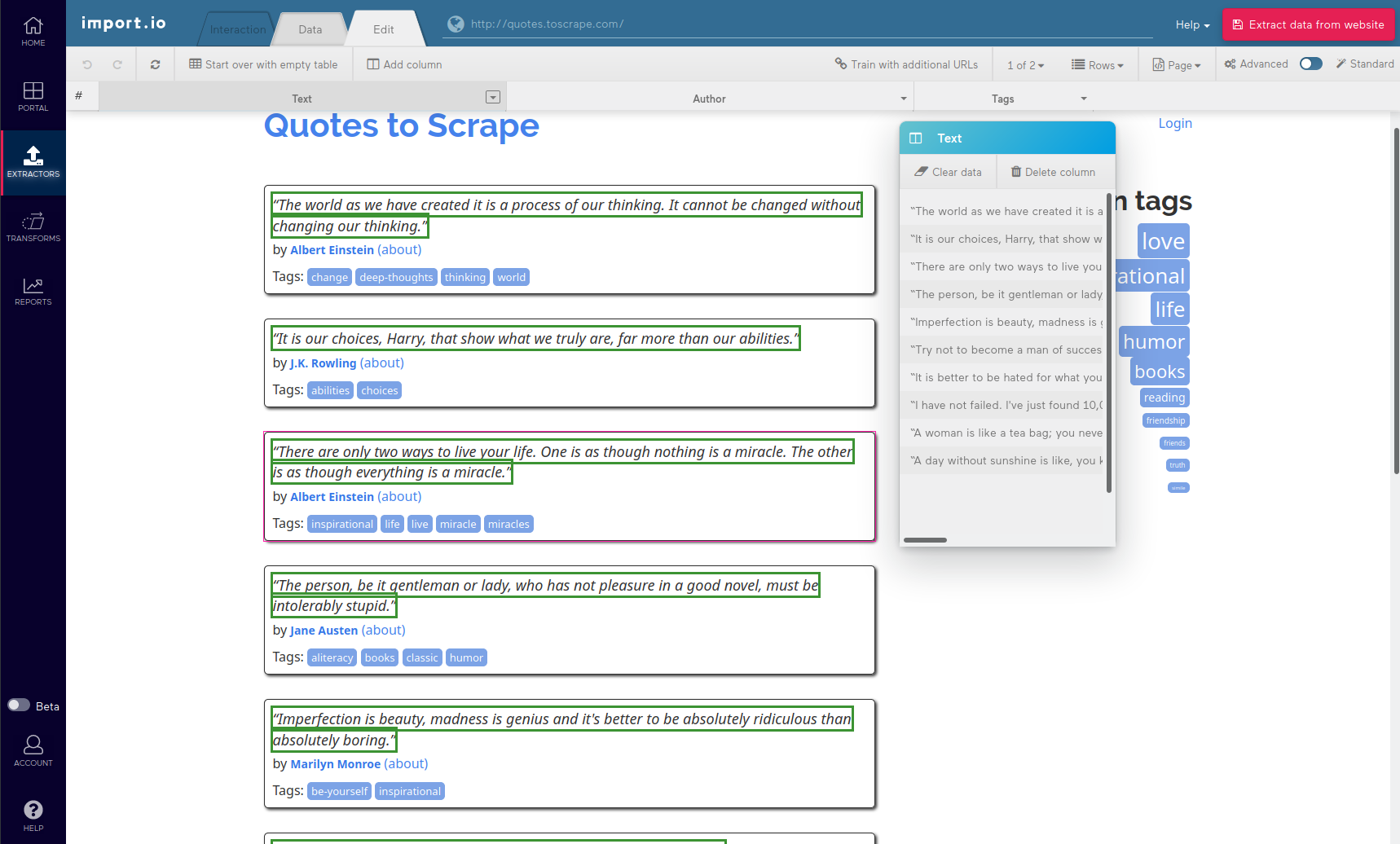
Advanced options are available for diffucult websites. These include disabling CSS and/or JavaScript, switching between single-row and multi-row extraction and the ability to provide additional URLs (e.g. for paginated content) to train the extractor.
Download of extracted data is possible in Excel, CSV and NDJSON formats. There is also a RESTful API endpoint available, and results can also be stored in the Cloud.
Once a scraper is saved, it can be configured to run regularly, for example once an hour or once a day. The reporting feature can be used to receive emails if items change between runs, which is useful to monitor the extraction.
Another interesting feature is that extractors can be chained - that is, the outputs of one extractor can be used as the input to another one. For example, one extractor could collect all the links to detail pages from a list of products. This would be the parent extractor. A child extractor would then use these urls as input, and for each url perform the extraction from the detail page. This method does not only work for urls, however. You could also use this technique for custom inputs. For example, you could collect a list of product names from one page in the parent extractor, and use these names as input to a search field on another website in the child extractor.
Webscraper.io
Webscraper.io is an extension for the Chrome browser which basically adds an additional tab to the Developer tools in Chrome. It is free, but running the designed Scrapers in the cloud on the WebScraper.io platform is fee-based, starting at $50/month for up to 5,000 pages.
Usage of this tool is rather intuitive and also robust. A diagram visualizes loops or recursions in the extraction workflow.
Elements are selected with the element picker that was able to almost always pick the correct element. It makes use of CSS selectors to identify the selected element.
Unfortunately, more complex tasks like logins or dropdown menus cannot be realized with this tool. Also additional features for interaction, such as reload or form fill, are missing.
Given that this is a free browser extension, WebScraper.io is a nice tool to extract data from static websites. It is possibly suited best for pages where a lot of data can be found in a list-like structure, without interactive elements.
Dexi.io
Dexi provides a web application to create and manage what they call robots, thus no installation is required.
There are actually four types of robots: Crawlers are given a start URL and simply visit each link they can find on that page. A crawler can also perform an action on each page visited. Extractors are those kinds of robots needed for web scraping from interactive pages. They can perform actions such as filling out forms or clicking buttons. The other two types of robots, Pipes and AutoBots are used for managing scrapers but do not perform scraping themselves.
We will focus on extractors here.
A new extractor is created by providing the target url. The working environment consists basically of two parts: The top panel is the browser displaying the target website. On the bottom is a diagram that represents the extraction workflow.
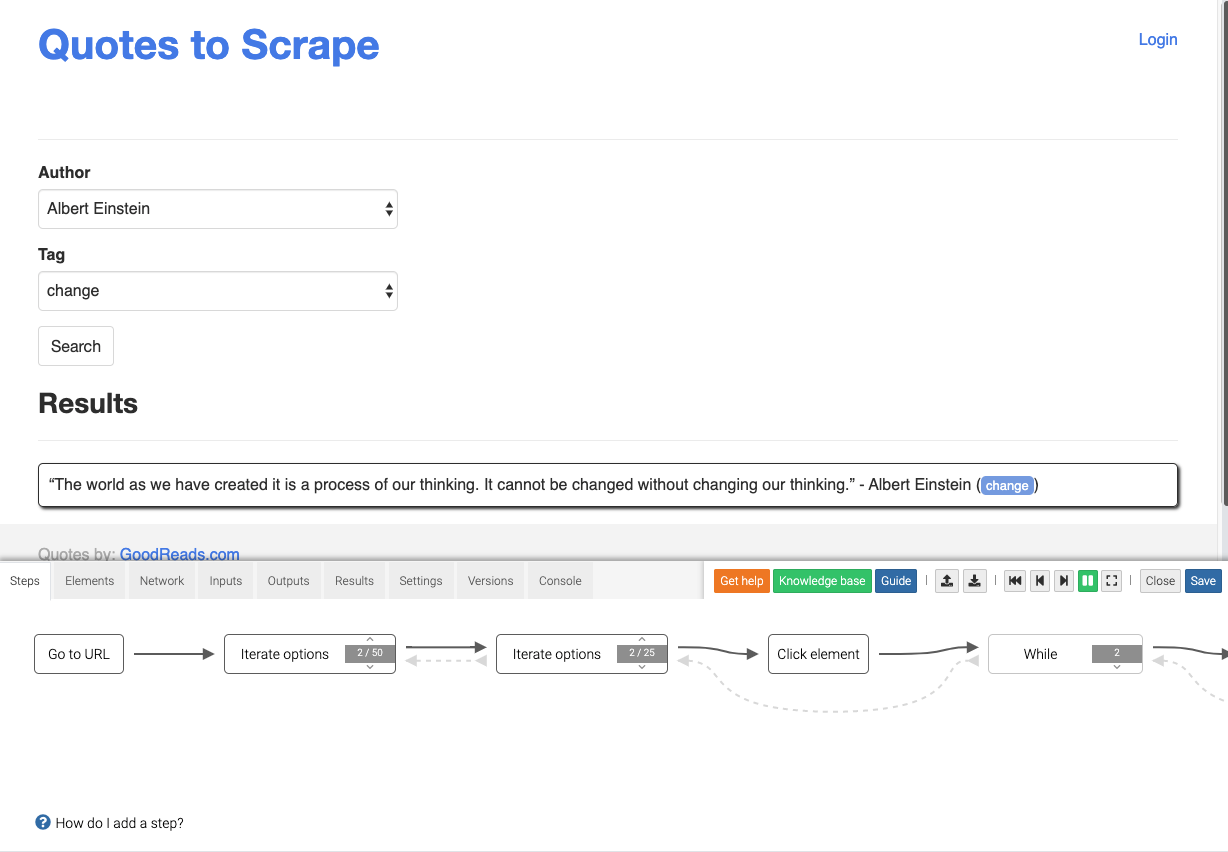
In general, Dexi was able to handle all the use cases we tested. The element picker did not always quite match what we intended, but we could adjust for this with setting some offset or increment interval. With some trial and error, we think that most use cases of the modern web can be addressed with this tool. The documentation could be improved upon, since it basically consists of a small collection of articles targeting specific problem settings.
The pricing model of Dexi is based on monthly subscription, starting at $119 for small projects. Pricier plans are designed for business-level use cases that need more capacity, faster execution and professional support. For a single fee of $189, the Dexi team will also build a robot for you based on a description of what data you need to get extracted from a given website.
Overview
Above, we have presented only a selection of web scraping tools in detail. There are plenty more tools available. An overview of all the tools we have had a look at during our project can be found below.
A ‘+’ in the table means, the tool can handle this feature, ‘-‘ means it does not. Parantheses mean that we were not able to test the feature, but the tool’s manual lists this capability. A ‘o’ indicates that the tool can only deal with the feature with limitations (for example, select only pre-defined options from a dropdown, or it is difficult to realize).
| Octoparse | Mozenda | WebHarvy | Visual Web Ripper | Excavator | ImportIO | WebScraper.io | Dexi.io | |
|---|---|---|---|---|---|---|---|---|
| pagination | + | + | + | + | + | (+) | + | + |
| popup links | + | + | + | (+) | - | (+) | + | + |
| AJAX pagination | + | + | + | + | - | (+) | + | + |
| ‘load more’ buttons | + | o | + | (-) | + | (+) | + | + |
| load scrolling | + | + | + | + | o | (+) | + | (+) |
| Javascript-generated content | + | + | + | + | - | (+) | + | + |
| tables | + | + | o | o | + | (+) | + | + |
| login / forms | + | + | + | + | - | (+) | - | + |
| dropdown menus | + | + | o | + | - | (+) | - | + |
| reload page | ? | ? | o | - | o | (-) | - | + |
Summary
In this article, we have presented a selection of web scraping tools for the layman. The described tools differ in mode of operation, functionality and cost. From the tabular comparison we saw that most tools have problems with tabular data, since tables on the web are often messy. Other challenges like AJAX generated content, handling dropdown menus and forms, as well as pagination and scrolling are handled well by most of the tools.
We hope this article has given you a good overview of available tools and helps you to choose the right tool for your task.
Additional software for web scraping can be found, for example, here or here.